
Health monitoring con Azure Container App
Abbiamo visto con gli scorsi script come possiamo ottenere tutti i vantaggi di un cluster Kubernetes (K8S), ma senza la sua complessitŕ di gestione, grazie ad Azure Container App.
Ci basta indicare l'immagine Docker, impostare le regole di scaling e al resto ci pensa Azure, il tutto con un approccio server less che ci permette anche di spendere nulla quando non stiamo usando il nostro container.
Il container di fatto č una console app che perň ha tempi di avvio e resta in vita per sempre. Se siamo "fortunati", errori gravi possono causare il crash del processo che essendo monitorato viene subito ripristinato. Puň succedere invece che il processo sia attivo, ma che in realtŕ non riesca a soddisfare le richieste via HTTP o via SQL, oppure sebbene risponda, non abbia tutta la filiera delle dipendenze (database, ecc) funzionante. Inoltre, quando il container parte non č detto che sia immediatamente pronto, perciň č necessario dire al gateway se effettivamente instradare le richieste sulla nuova istanza/replica.
Per tutte queste ragioni, note se abbiamo giŕ gestito un cluster K8S, su Azure Container App possiamo impostare le regole di health probe, rispettivamente per:
- Liveness: per monitorare lo stato di salute generale;
- Readiness: per monitorare se č in grado di accettare il traffico;
- Startup: per avvi lunghi e ritardare quindi l'avvio dei due precedenti monitor.
Tutto questo č basato sullo stesso motore di K8S ed č configurabile attraverso la sezione health probes in fase di deploy di un container.
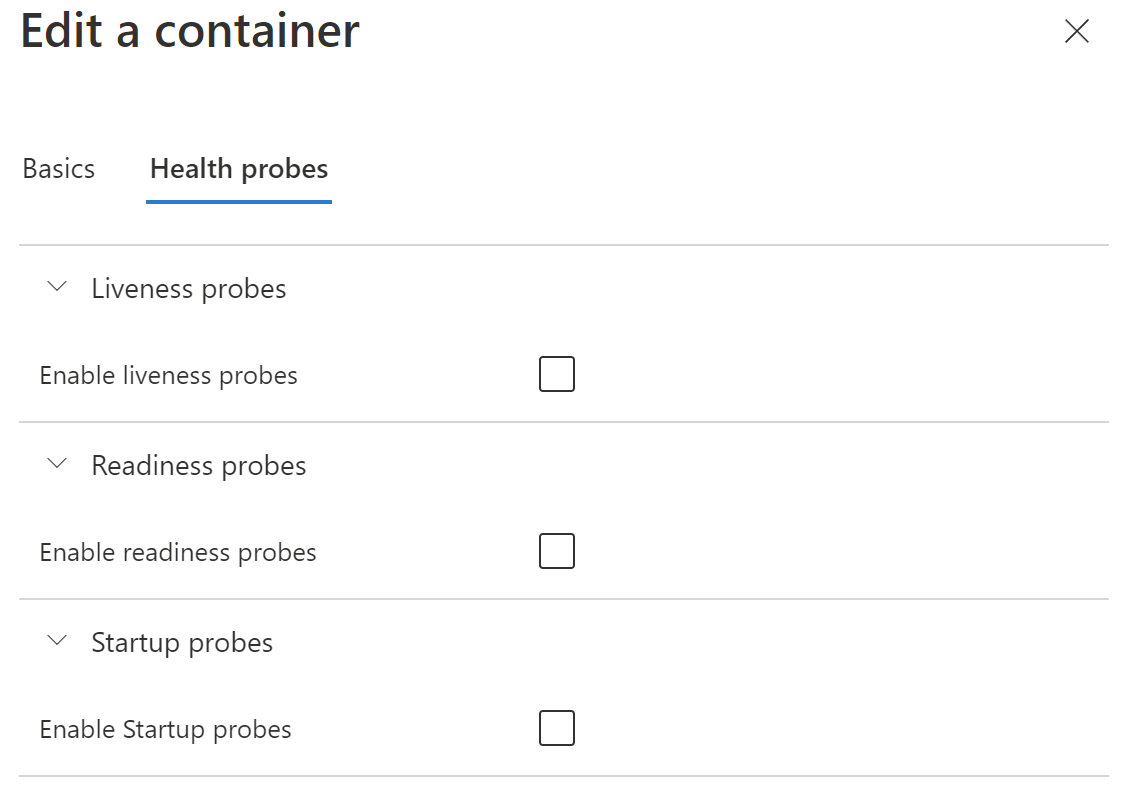
Possiamo abilitare singolarmente il tipo di monitor ognuno dei quali presenta la stessa configurazione. Innanzitutto, il monitor si basa sull'interrogare regolarmente un endpoint HTTP o TCP. Nel primo caso si verifica lo status code della risposta, che sia tra 200 e minore di 400. Nel secondo caso il motore verifica che sia possibile una connessione TCP.
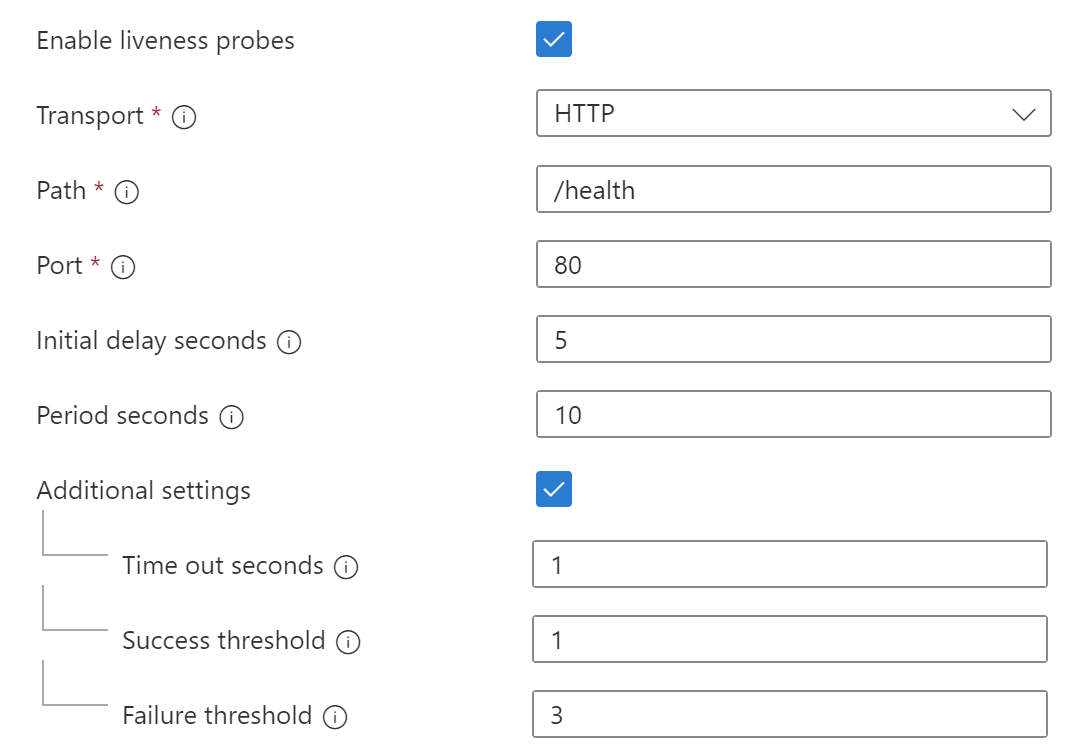
Dobbiamo quindi indicare il percorso da chiamare (nel caso di HTTP), eventuali secondi di attesa prima di cominciare a fare le verifiche (5 secondi), ogni quanti secondi controllare il percorso (10 secondi), quanto tempo massimo aspettare per una risposta (1 secondo), quante risposte sono necessarie per considerare in salute il processo (1) e quante risposte non valide per considerare fallito il processo (3).
Consigliamo quindi di impostare sembra almeno una di queste regole per garantire l'affidabilitŕ.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Disabilitare le run concorrenti di una pipeline di Azure DevOps
Creare agenti facilmente con Azure AI Agent Service
Escludere alcuni file da GitHub Secret Scanning
Utilizzare il metodo ExceptBy per eseguire operazione di sottrazione tra liste
Utilizzare il metodo IntersectBy per eseguire l'intersection di due liste
Gestione dell'annidamento delle regole dei layer in CSS
Collegare applicazioni server e client con .NET Aspire
Configurare il nome della run di un workflow di GitHub in base al contesto di esecuzione
Sfruttare GPT-4o realtime su Azure Open AI per conversazioni vocali
Il nuovo controllo Range di Blazor 9
Utilizzare Copilot con Azure Cosmos DB
Referenziare un @layer più alto in CSS



