Integrare e trasformare dati con Azure Data Factory


Con l'avvento del cloud gli applicativi, le loro funzionalità e il loro utilizzo si è amplificato a dismisura. Di conseguenza anche i dati sono diventati sempre di più, grazie anche al fatto che la loro memorizzazione è sempre più economica e alla portata di tutti, soprattutto nella loro gestione. I big data, quindi, rappresentano una nuova risorsa, che da una parte bisogna saper gestire, dall'altra anche interpretare. E' normale quindi trovarsi di fronte ad esigenze vecchie come l'informatica stessa, come l'estrapolazione e la trasformazione di questi dati, e di necessitare di un ETL (extract, transform, load). Questo strumento però, deve considerare l'enorme disomogeneità di fonte dati e tipologie di database, e allo stesso tempo poter processare GB o TB di dati.
Azure Data Factory è l'implementazione di Microsoft Azure che raccoglie tutte queste esigenze offrendole come PaaS, il tutto basandosi su Apache Spark, un motore consolidato e ampiamento utilizzato. Possiamo quindi scalare facilmente, a seconda della quantità di dati da processare, e pagare solo lo stretto necessario dovuto all'elaborazione. In questo articolo vogliamo quindi introdurre questo servizio e affrontare le sue caratteristiche principali, per capire come riuscire a processare i nostri dati.
Come ogni servizio della piattaforma Microsoft Azure, anche Data Factory necessita di creare un'istanza in una delle regioni disponibili. Poco ci viene chiesto, come il classico nome o i requisiti di rete.
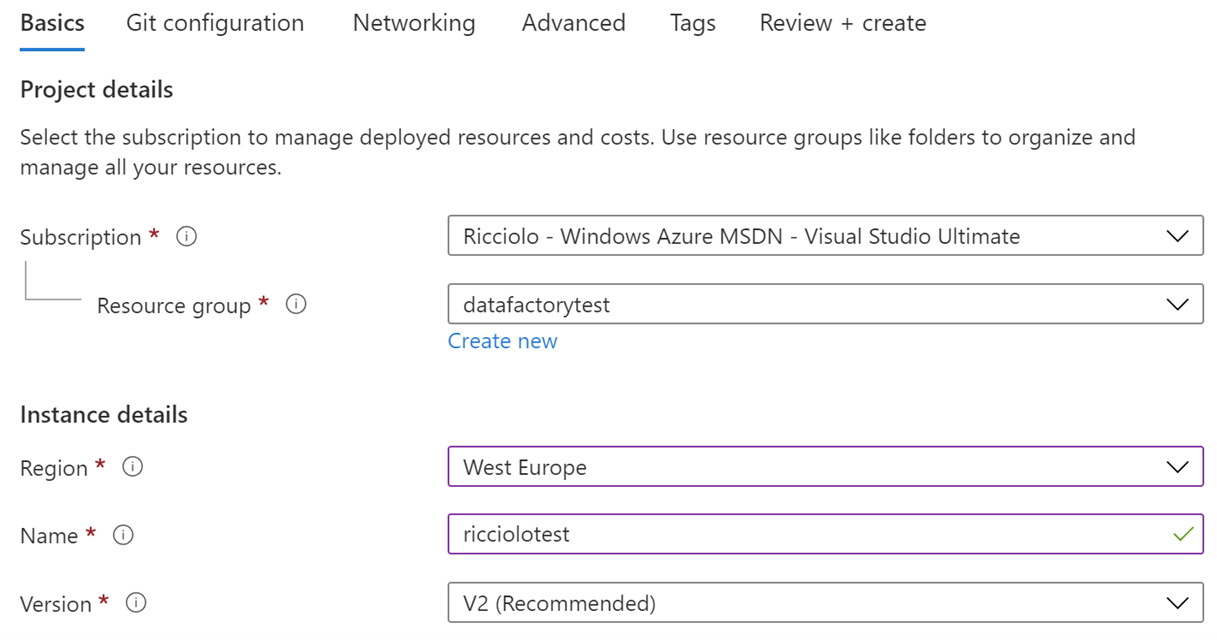
Di particolare, però, ci viene chiesto se vogliamo integrare un repository Git, in modo da gestire gli elementi di configurazione delle trasformazioni attraverso file JSON persistiti su un repository e beneficiando di caratteristiche come la history e le branch.
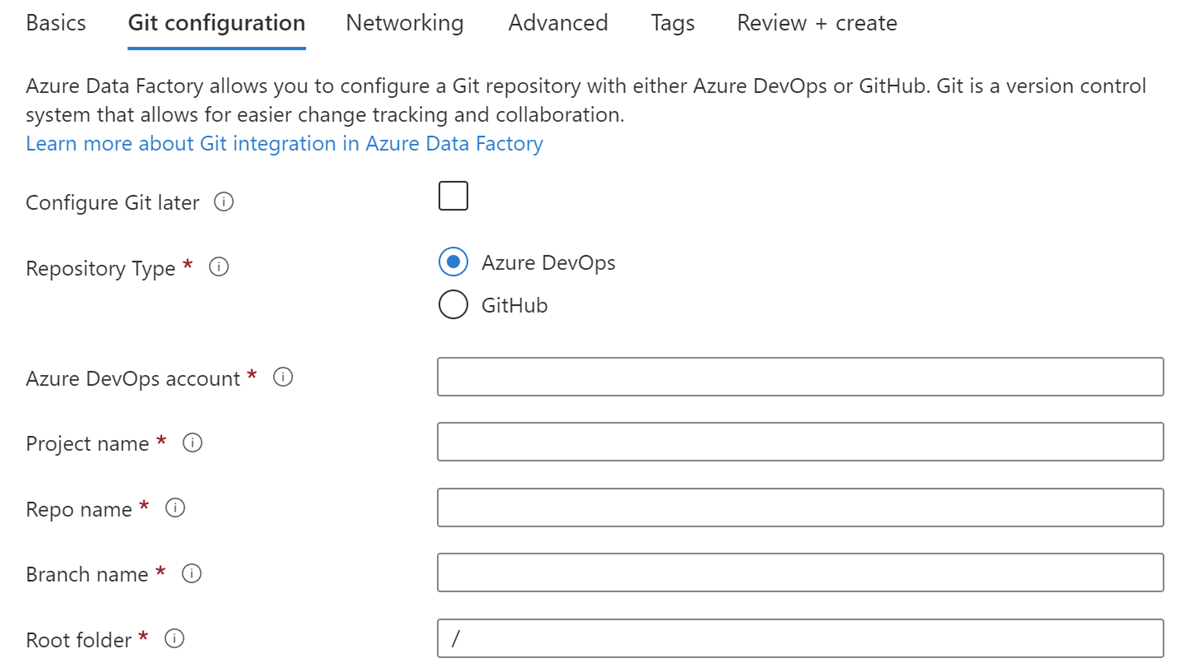
Possiamo effettuare questa configurazione anche successivamente. Creata l'istanza, il pannello Azure ci permette solamente di monitorare utilizzo e prestazioni. Il tutto è infatti demandato all'Azure Data Factory Studio, un ambiente web di disegno dei nostri ETL.
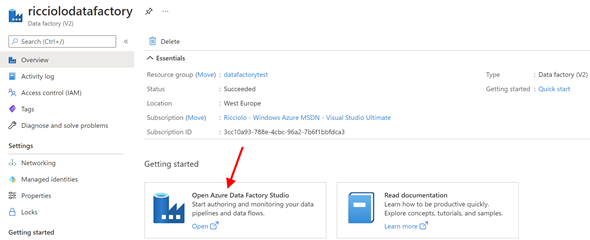
Si apre così un nuovo ambiente dedicato al disegno, al monitoraggio e alla gestione della nostra istanza.
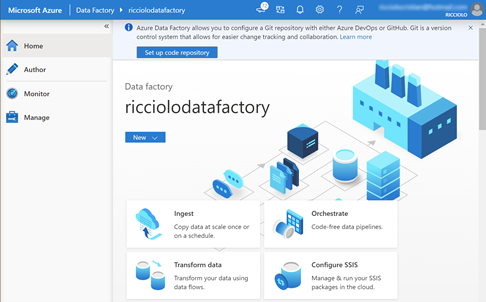
Il motore si compone di alcuni concetti basilari che permettono poi di operare. Le pipeline sono il cuore di esso e definiscono le attività da svolgere, come caricare, processare o scrivere dati. I dataflow hanno il compito di ricevere input e output da leggere o scrivere all'interno di dataset. Vengono attivate da trigger che possono essere temporali o in base ad un input, ed eseguite all'interno di runtime che definiscono la capacità, in termini di CPU e RAM disponibile. Questi concetti chiave sono la base per partire e definire i nostri processi, ma prima di tutto è necessario configurare l'ambiente.

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Iscriviti alla nostra newsletter nuoviarticoli per ricevere via e-mail le notifiche!



